Problem Statement:
Given a file of text, output what all words appear in the file and how many times.
In typical, not distributed environment, to solve this problem, one would need to process the file may be a line at a time and track word counts in a data-structure like a map.
Here we will see how we can solve this problem the Spark way. Well! Spark ways. We will see how we can solve this with :
- RDD
- DataSet
- DataSet with SQL
RDD
Let’s first jump into the code.
private static void rddApproach() {
SparkConf conf = new SparkConf()
.setAppName("RDD Word Count")
.setMaster("local[*]");
JavaSparkContext sc = new JavaSparkContext(conf);
final JavaRDD<String> fileRdd = sc.textFile(FILE_PATH);
final JavaPairRDD<String, Integer> words = fileRdd
.flatMapToPair(new PairFlatMapFunction<String, String, Integer>() {
@Override
public Iterator<Tuple2<String, Integer>> call(String s) throws Exception {
final String[] split = s.split("[^a-zA-Z0-9]");
return Arrays.stream(split)
.filter(str -> str.trim().length() > 0)
.map(str -> new Tuple2<String, Integer>(str, 1))
.iterator();
}
});
final JavaPairRDD<String, Integer> wordCountRdd = words
.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer count1, Integer count2) throws Exception {
return count1 + count2;
}
});
wordCountRdd.foreach(wc -> System.out.println(wc._1 + " ==> " + wc._2));
sc.close();
}We first start by creating a Spark Config mentioning the Spark Application Name and Master as local to run locally. When you run this in some cluster, you need to change Mater value.
Then we create Spark Context with JavaSparkContext which is Java specific way to create a new Spark Context.
Spark Context acts as a gateway to Spark World. It is created on the driver. It helps Driver to talk to underlying cluster for resource management and task scheduling.
Once we have SparkContext, we use textFile to read a text file from given path. This reads the file into RDD where each RDD item is a line from the file.
Then we use flatMapToPair to convert each line from the file into words. So the output JavaPairRDD has each item as word as its first element and count 1 as its second element.
There are similar transformations to flatMapToPair like:
- map
- Transformation which converts each RDD item to different item. More like Java Stream
mapfunction.
- Transformation which converts each RDD item to different item. More like Java Stream
- mapToPair:
- Like map, but instead of JavaRDD it converts RDD items to JavaPairRDD items, each with two sub items like a tuple
- flatMap
- Transformation which converts each RDD item to 0 or more Different items.
- flatMapToPair:
- Like flatMap, but instead of JavaRDD it converts RDD items to 0 or more JavaPairRDD items, each with two sub items like a tuple
Then we use reduceByKey to perform sum of count reduction on the pair RDD.
The PairRDD returned from last flatMapToPair transformation has count as 1 and we now reduce by the word and sum up the count to get total count of each word.
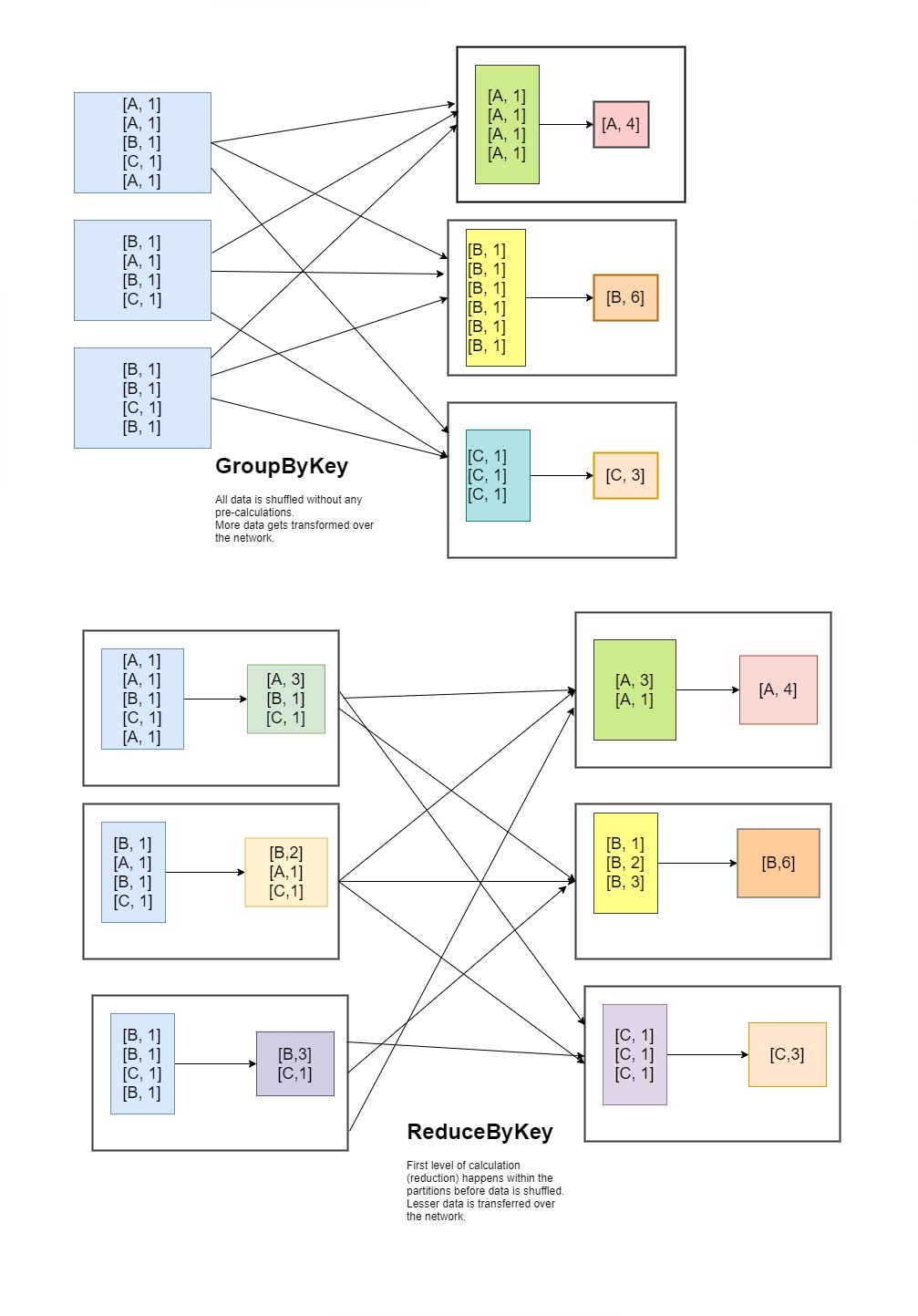
There is similar transformation to reduceByKey called groupByKey but there is a subtle difference in how the internally shuffle the data.
groupByKey when performed on the RDD causes entire data on all the partitions to be shuffled across all the executors to bring all data of each key into single new partition. This is a lot of data shuffling and causes performance bottleneck.
reduceByKey also causes data to be shuffled but before data is shuffled, the reduce operation is performed on the data in each partition by the keys resulting in lesser data being shuffled as it calculates reduction and then shuffles the intermediate results only and not all the records.
Following diagram shows the behavioral difference between ReduceByKey and GroupByKey.
DataSet
DataSet/DataFrame is new way to write Spark Code which is more friendly and is more flexible. It is more SQL friendly as to have SQL like methods to manipulate data.
Code is here:
private static void dataFrameApproach() {
System.setProperty("hadoop.home.dir", "C:\\programs\\hadoop");
Logger.getLogger("org.apache").setLevel(Level.WARN);
SparkSession spark = SparkSession.builder()
.master("local[*]")
.appName("DataSet Word Count")
.config("spark.sql.warehouse.dir", "file///c:/tmp/")
.getOrCreate();
final Dataset<Row> fileDataSet = spark.read().text(FILE_PATH);
StructType stringCountSchema = new StructType()
.add("word", DataTypes.StringType)
.add("count", DataTypes.LongType);
final ExpressionEncoder<Row> stringCountEncoder = RowEncoder.apply(stringCountSchema);
final Dataset<Row> wordsWithCount1 = fileDataSet.flatMap(new FlatMapFunction<Row, Row>() {
@Override
public Iterator<Row> call(Row row) throws Exception {
final String[] split = row.getString(0).split("[^a-zA-Z0-9]");
return Arrays.stream(split)
.filter(Objects::nonNull)
.filter(str -> str.trim().length() > 0)
.map(str -> RowFactory.create(str, 1L))
.iterator();
}
}, stringCountEncoder);
final Dataset<Row> wordCount = wordsWithCount1.groupBy(col("word")).agg(sum(col("count")));
wordCount.show(100, false);
spark.close();
}The code starts of by setting some properties
- Hadoop home directory: for I was running the code on Windows machine.
- Setting apache logs to warn level to reduce the noise.
Next we create SparkSession, which is used where we used to use SparkContext in RDD. Spark session incorporates legacy SparkContext and other contexts; and performs all the things SparkContext was used for. Just like context, the SparkSession also takes the app name and master configurations.
Then we use SparkSession to read a text file from given path to read lines into DataSet of Rows, where each row represents a line from the file.
Each Row DataSet needs to have schema mentioning the fields and types they have. This DataSet of Row returned after reading a file has a schema as
valuefield of type String.
Next we need to split each line into words. That transformation should return another DataSet of Row. But this new Row DataSet needs to have two columns (fields) as
- word: String column to hold the word
- count: Long column to hold the count, initialized to 1.
For this transformation we use the FlatMap converting each line into words with count as 1. But for this method, we need to provide the meta data as to how to encode these values when they are transferred between the executors.
We have inbuilt Encoders for well known types like String, Long etc. Also we can build ones for Specific Class with Encoders.bean() and Encoders.kyro().
But for this simple use case we don’t need to create a new class. We can just create an RowEncoder from schema which we define with StructType mentioning the column names and types.
In our case we would have word String and count Long as defined in the code.
Once we have Row DataSet with word and count, we use SQLish methods from DataSet to perform groupBy word and sum aggregation on count with groupBy and agg methods.
We can define columns like word, count with function.col helper methods for building Column objects. There exists overloaded methods which takes string names of columns or index of columns.
After this aggregation we get the result we want that we print to output with show.
Then we close the Spark Session.
This DataSet ways of writing Spark code is new one but behind the scene it uses RDD only. DataSet operations are way more friendly that RDD.
DataSet with SQL
This approach is based on DataSet only but explicitly uses SQL queries to be run on DataSet instead of DataSet methods.
Reading data and basic transformations are same as that of earlier method.
private static void dataFrameSQLApproach() {
System.setProperty("hadoop.home.dir", "C:\\programs\\hadoop");
Logger.getLogger("org.apache").setLevel(Level.WARN);
SparkSession spark = SparkSession.builder()
.master("local[*]")
.appName("DataSet Word Count")
.config("spark.sql.warehouse.dir", "file///c:/tmp/")
.getOrCreate();
final Dataset<Row> fileDataSet = spark.read().text(FILE_PATH);
StructType stringCountSchema = new StructType()
.add("word", DataTypes.StringType)
.add("count", DataTypes.LongType);
final ExpressionEncoder<Row> stringCountEncoder = RowEncoder.apply(stringCountSchema);
final Dataset<Row> wordsWithCount1 = fileDataSet.flatMap(new FlatMapFunction<Row, Row>() {
@Override
public Iterator<Row> call(Row row) throws Exception {
final String[] split = row.getString(0).split("[^a-zA-Z0-9]");
return Arrays.stream(split)
.filter(Objects::nonNull)
.filter(str -> str.trim().length() > 0)
.map(str -> RowFactory.create(str, 1L))
.iterator();
}
}, stringCountEncoder);
wordsWithCount1.createOrReplaceTempView("words");
final Dataset<Row> wordCount = spark.sql("select str, sum(count) from words group by str");
wordCount.show(100, false);
spark.close();
}Once we have data in DataSet rows with word and 1 as count then we create a temp view from it with createOrReplaceTempView with table name as words.
After that we just run SQL to get the data we want by using SparkSession.
This SQL query returns us the Dataset of Rows in correct schema.
Then follows the print and closing the session.
Conclusion
Of the three approaches discussed above, 2nd one with DataSet is what I personally prefer as it is more friendly and not a black-box like 3rd one.
SQL way is best suitable when we want to run ad hoc queries on data or to perform queries based on user configured inputs as it is easier to convert user requirements into SQL than RDD or DataSet manipulation code.