Spark is distributed data processing framework used in Big Data world to process a big amount of data in a distributed way to process it parallelly and so faster.
Spark supports processing data in batch mode as well as running continues stream of data in streaming mode.
Its distributed nature makes processing scalable and fault tolerant.
Distributed Nature
Basic unit of Spark Data is Resilient Distributed DataSet (RDD).
Resilient
RDD in spark is Immutable. When you read some data into RDD, first RDD is created. When you perform any operation on it, it returns the new RDD. Another operation on this RDD returns yet another new RDD.
This immutable nature of RDD makes Spark flow more fault tolerant in other words Resilient, because if some operation fails, it can be safely retried as input RDD of it is immutable. Had it been mutable, on failure, we could not have retired the operation so easily.
Distributed
When some operation is to be performed on the RDD, the RDD is basically split into multiple data units, each of which is independently acted on in different executors.
A data unit along with the code/operation to act on it is called a Task, which forms basic unit of processing for Spark. And these tasks are executed on multiple executors in parallel which makes Spark processing so fast.
Components of Architecture
Spark at it’s core has two basic components
- Driver
- Executors
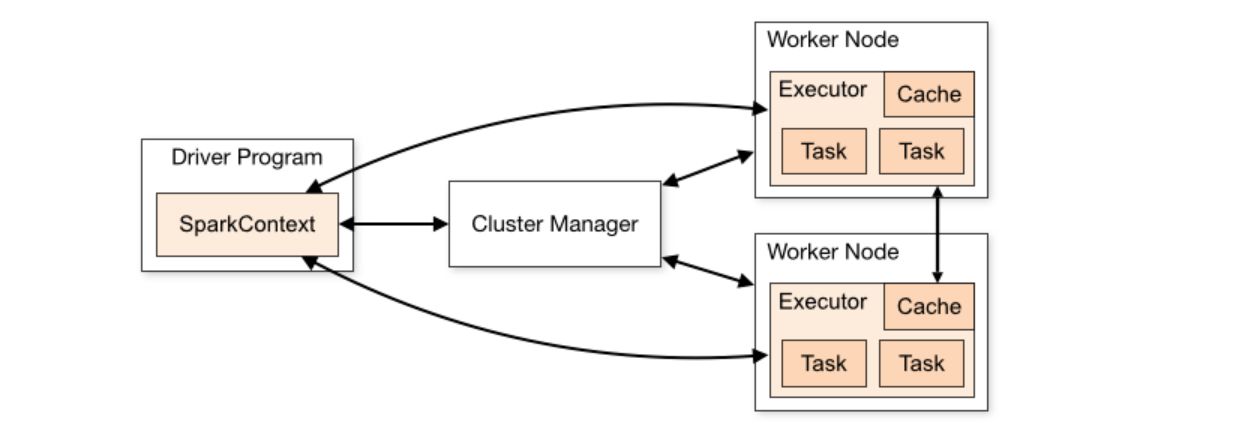
Spark follows master slave architecture. Here Driver acts as a master while multiple executors act as slaves.
Another cool feature of Spark is that it does not make any assumptions about underlying cluster. We can run Spark job on a YARN cluster, Kubernetes cluster or in standalone mode.
Driver
Driver is the master, responsible for running your job. For every Spark job, it runs a Driver process.
It runs main function of the Spark Job you submit. It is responsible for
- Building the DAG (Directed Acyclic Graph)
- Talking to underlying resource manager to request resources for running executors
- Maintain metadata about the Spark Job and expose it over the WebUI.
- Distributing the data into chunks, building tasks from them and scheduling those tasks to be run on the executors.
Spark supports running Spark Job in two Deploy Modes which define where and how the driver of the Job would run.
- –deploy-mode cluster
- In this case, driver of the Job runs on the one of the worker nodes of the cluster.
- Once job is submitted this way, the process which submitted the Job can be killed without killing the job as the Driver is running on the cluster.
- We always run spark in production in cluster mode only.
- Underlying cluster like YARN provides details and ways to manage these driver programs
- –deploy-mode client
- In client mode, the process submitting the Job itself acts as a driver.
- If we kill the process submitting the Job, Driver of the Job gets killed.
- Not used in production, can be used for local debugging.
Executors
Executors are the slaves in Spark. Executors perform tasks assigned to them.
Executors are responsible for
- Running tasks.
- Hold intermittent data in-memory or on Disks.
- Read or Write from external sources if required.
Job, Stage, Task
In a given Spark Application (usually called as a Job), we can have multiple actions producing multiple results. Such action could end up returning some data as a result or writing some data to some storage.
Say suppose, we have RDD and we write that into HDFS and after that we also print the size of the RDD, then these two are distinct actions. Each one resulting into different Jobs.
In Spark, only when some action is performed in pipeline of operations that we actually start executing the Spark Job. If we just have some transformations on the data and no action, Spark does nothing.
That way, we have two types of operation on RDD in Spark.
- Transformations
- These transform one RDD into another.
- Any transformation does not trigger actual processing.
- Eg. filter: creates new RDD from input RDD with data matching some condition
- Action
- These are actual collectors which creates some result from the RDDs.
- These results could be in the form of storing them in some store and returning some actual data (NON-RDD).
- Eg. count: outputs number of items in the RDD.
For Transformations, there again two types of transformations.
- Wide Transformation
- Transformation which requires shuffling of data between different tasks are Wide Transformations.
- To perform these transformation completely, processing each dataset independently is not enough. We need to merge intermediate results to generate final result.
- Eg. groupByKey, reduceByKey
- Narrow Transformation
- Narrow transformations don’t need to shuffle or merge complete dataset to perform operations.
- These transformation can be performed in each dataset independent of other and their intermediate results need not be shuffled or merged to form final result.
- Eg. map, filter.
When there is wide transformation in the sequence of operations, data shuffling is required. So logically it creates different datasets. So all the tasks performed until this can be performed independent of each other.
These transformations until some Wide Transformation, together form a Stage.
And each of these stages have multiple Tasks, where each task is data and the operation to be performed on it.
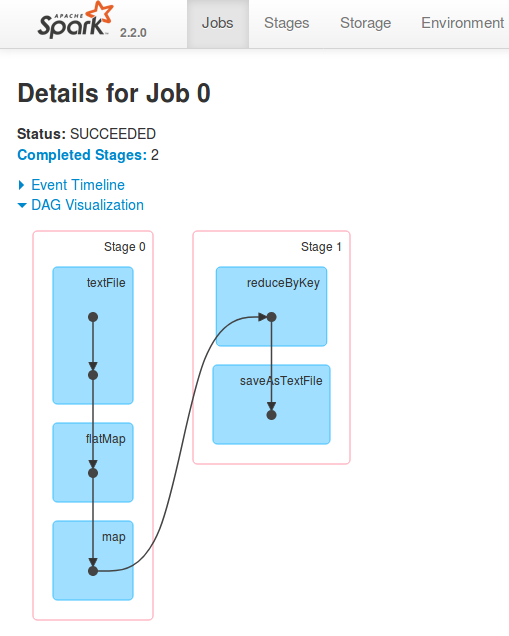
DAG
When Spark starts processing the application, the driver creates a logical plan as to how it should be executed and what all tasks are involved.
As mentioned earlier, just like Java Streams, no transformations are performed until actions are found to be performed.
All these tasks are arranged in a Directed Acyclic Graph. If there exists any wide transformations it results in DAG having a new stages. So DAG itself presents grouping of Tasks into Stages and Stages into Jobs.
One can go to Spark UI, and see DAG under Jobs tab. It shows visual presentation of the DAG.
DAG Scheduler then creates a Physical Execution Plan from the Logical Plan after identifying and performing possible optimizations. This physical plan contains tasks which would be bundled together to be send to executors in the cluster.