Elastic Search is a horizontally scalable search engine with support for near real time search. Here, we will go over how this Elastic Search does it.
Before we know how it internally behave, we need to know some concepts of Elastic Search.
Document
A document is a single record of data we store in Elastic. It is in JSON format with key value pairs. Where keys are the fields of the records that you can search on.
Eg.
{
"name": "Nilesh Injulkar",
"birth_date": "1995/05/18",
"skills": ["programming", "reading"]
}Index
Index is collection of related documents. It is like a table in RDBMS. While searching, you can search across single or multiple indices. Eg. Index users can store users with fields like name, birth_date, skills.
Template
Template acts as a schema for an Index, and defines what all fields and of what types would be there in index.
Shard
Each index has multiple shards. Default is 5 shards. Shard is where documents are stored. Having documents stored across multiple shards enables searching index in parallel way as shards would be searched in parallel and results from multiple shards are put together to form final results.
Primary and Replication Shards
Each shard is duplicated for purpose of redundancy as well as more parallelism. One main copy of a shard is called primary shard and duplicated shards are called replicas. On search, data is searched on primary or replication shards allowing more load spreading as search is not limited to primary ones only.
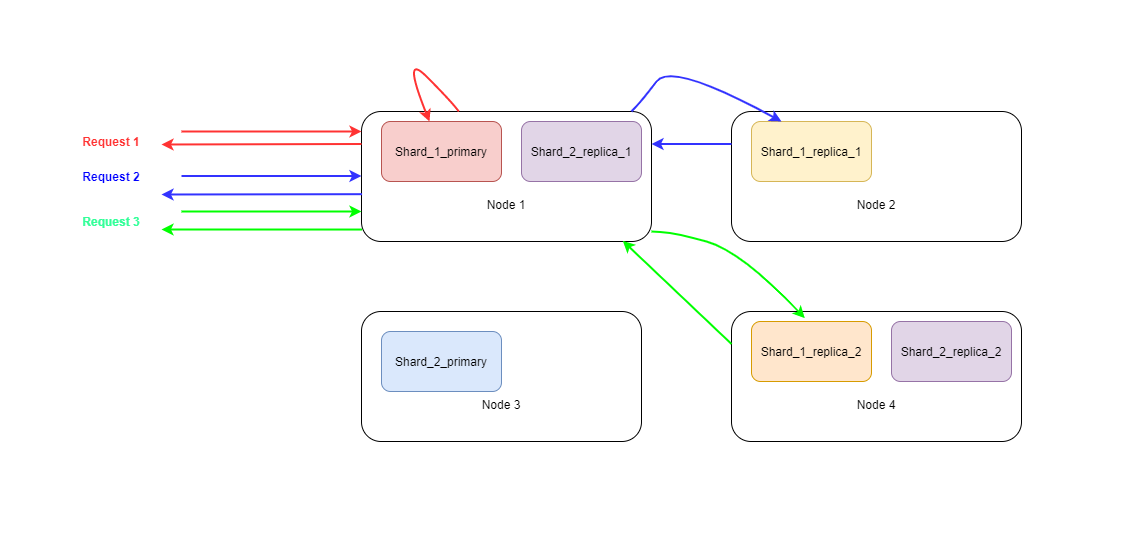
Coordinating Node
When search is performed on ES cluster, we can connect to any of the nodes as each one knows same detail of the cluster mainly about on which shard and on which node document with specific id is stored. It acts as a client to the current request and does merging of results of distributed queries.
Document Id and Hashing
Each document in elastic has user provided or system generated id. This id also acts as a default routing parameter for the document deciding on which shard of the index would it be stored. Elastic Search decides shard for given document by following formula:
#shard = hash(routing_param)/number_of_shards
For this reason, when index is created we need to fix number of shards it should have as it is used in above formula.
Search By Id
When we need to get a document by id, we request to the coordination node for document with id with API GET my-index/_doc/id
When byId request is received, the coordination node figures out the shard where the document should be stored by the formula described above which is same as the one used while storing (indexing) the document.
Once we know the shard, request is forwarded to the one of the primary or replicated shards which could be on any of the nodes. For fetch of the of the same document next time, request is forwarded to another copy of the shard.
Eg. If index is configured with 2 replication factor, there would be 3 copies of each shard: one primary and 2 replicas. First request for document X could go to replica number 1, next one for same document could go to primary and then new next one could go to replica 2.
If we had limited search to only primary node, all requests would cause load on the single copy of the shard. But with this distributed round robin search load is distributed across multiple copies of the shards. So, shard replication helps with node failure safety with replication as well as load distribution with serving search requests.
Text Search
Biggest benefit and performance Elastic Search brings to the table is for full free text search it supports. For search based on text, Elastic Search uses data structure called inverted index. For search on text we need to search on specific field. We can put together multiple conditions on multiple fields in a single query but that is based on composition of multiple single field queries. To search on entire document in any field, Elastic Search supports special field called _all which actually holds string representation of the document so that search on _all acts like search on entire document.
Under the hood, elastic search maintains inverted index for each field for the index.
For documents of index user as mentioned above, there would be one inverted index per each string type field. In above case, name and skills (and _all).
Inverted index is just a map from each word for field value to the document identifier. For below documents, inverted index for name field would have
[
{
"id": "d1",
"name": "Nilesh Injulkar",
"birth_date": "1995/05/18",
"skills": ["programming", "reading"]
},
{
"id": "id2"
"name": "Sagar Injulkar",
"birth_date": "1993/02/21",
"skills": ["computers", "reading"]
},
]nilesh -> d1
injulkar -> d1, d2
sagar -> d2
Not to be covered in this post but each string value and query string goes through same process of tokenization to convert string into tokens to be saved into or searched from the inverted index.
Eg. Nilesh Injulkar is tokenized by default analyser into nilesh and injulkar using space separation and lower case conversion.
And that is how nilesh and injulkar becomes keys in the inverted index for the name field.
When we search by InjulkaR the actual lookup in inverted index happens for injulkar and matches both documents d1 and d2.
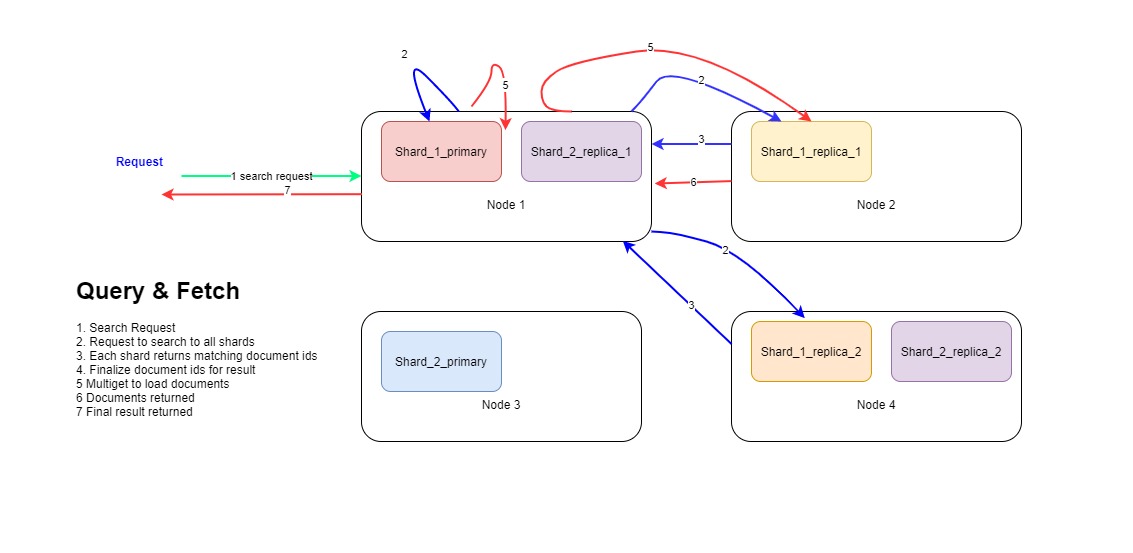
Query and Fetch
When there is a text search for a field, the search is divided into two stages namely
- Query
- Fetch
Query
In query stage, the coordinating node which has received the request searches all the shards for matching documents in following steps.
-
Coordinating node forwards search request to one copy of each shard. Copy of shard could be primary or replication. Suppose index has 5 shards, each with 2 replication; then request is forwarded to all 5 shards where for each shard one of the 3 (1 primary and 2 replication) copy is selected in round robin fashion.
-
Each shard, primary or replication on receiving the search request, does lookup into inverted index of the searched field and finds matching documents; well, only the ids of the documents matching.
-
How many documents to match depends upon
sizeandfromparameters of the request if request is paginated. Say forfromof 90 andsizeof 10, it selects at most (page + size) 100 documents sorted by default by_scoreof the documents or by sort attribute mentioned in the request. -
Event the output result is expected to be of at most size 10, we need to return 100 document ids from each shard. This is because search on shards are performed in parallel and we don’t know what 10 items (from 90th to 100th) would really belongs in final result for the selected range.
-
Result from each shard comes sorted in the form of priority queue. Each shard here puts 100 items into priority queue in sort order by sort attribute or _score.
-
When coordinating node receives results from all the shards, assuming each shard returns 100 items, for 5 shards the coordinating node receives 500 items. Then the coordinating node merges these 500 items into a priority queue sorted by sort attribute or _score.
-
Coordinating node then selects 10 items according to
sizefrom 90th to 100th items from sorted priority queue according tofromandsizeattributes.
GET /_search
{
"from": 90,
"size": 10,
"query": {
"match": {
"name": "injulkar"
}
}
}After this comes fetch stage as we only have the document ids as of now not the actual documents.
Fetch
Once coordinating node knows the documentIds it needs to fetch as a result of the request, it can now fetch only those docs. It already knows what all shards holds those documents.
The coordinating node makes mget (mulit get) requests to shards that it knows to contain the finalized 10 documents that it needs to include in the final result.
Once all these shards have returned the result, coordinating node returns final result to the client.
Following diagram depicts the flow mentioned above:
Deep Pagination
From above flow, you must have noticed one issue that for fetching 10 documents from the pages, each shard had to figure out 100 documents each and coordinating node had to handle 500 documents.
Consider the case when you want to fetch 10 documents but from page ‘from’ argument of value 20,000. For this each shard has to figure out upto top 20,010 documents and return in query phase and then coordinating node has to handle 5 (number of shards) * 20,010 = 100,050 documents, sort them and figure out the required 10 documents for next fetch phase.
This is a heavy operations and may cause performance bottleneck or event node failures. That is why Elastic Search does not recommend such deep pagination and by default, limits you from using from and size to page through more than 10,000 hits. This limit is configured with index.max_result_window index setting.
There are many more processes, not included in this post, that come into picture when actual search queries are executed.